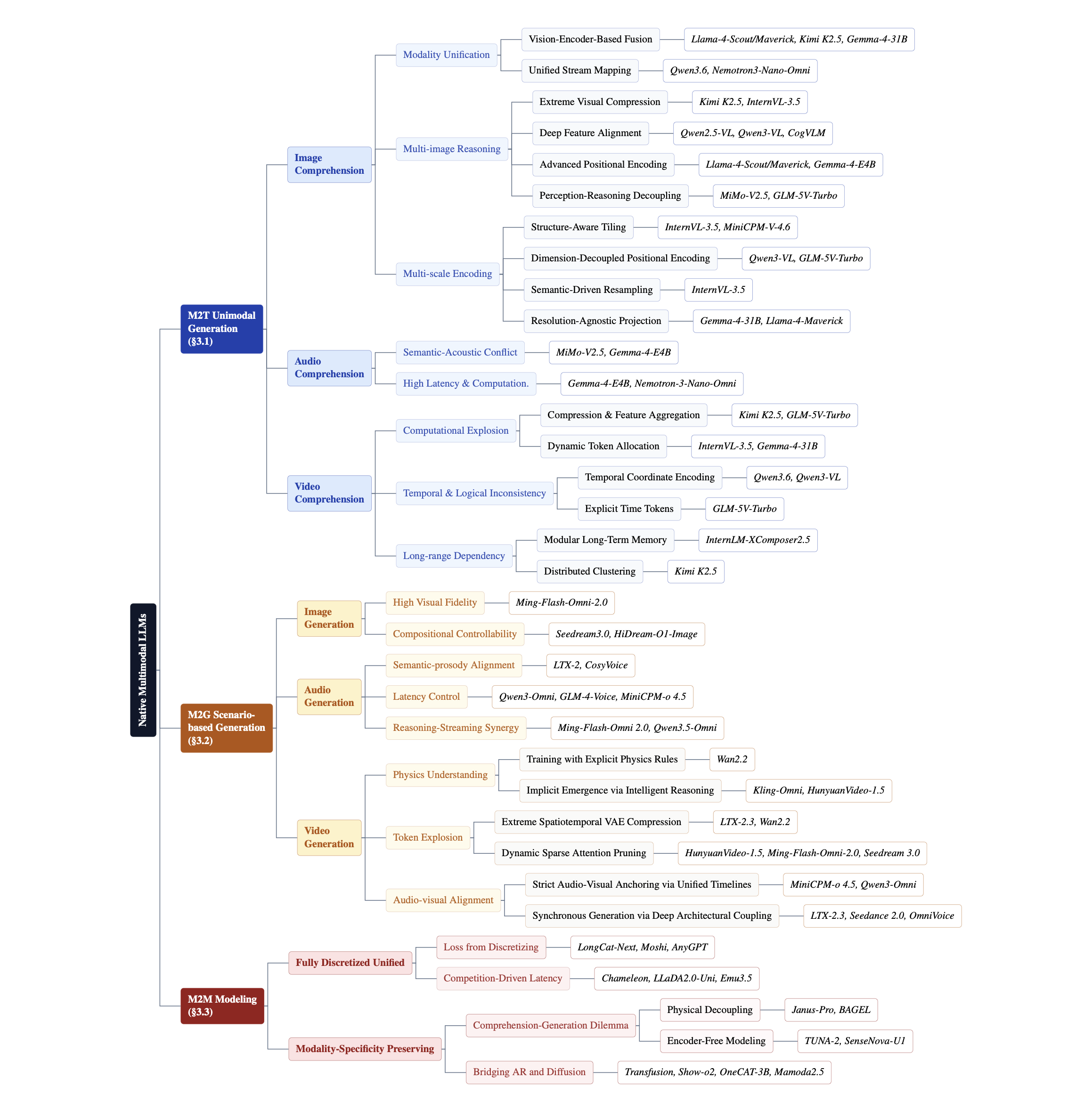
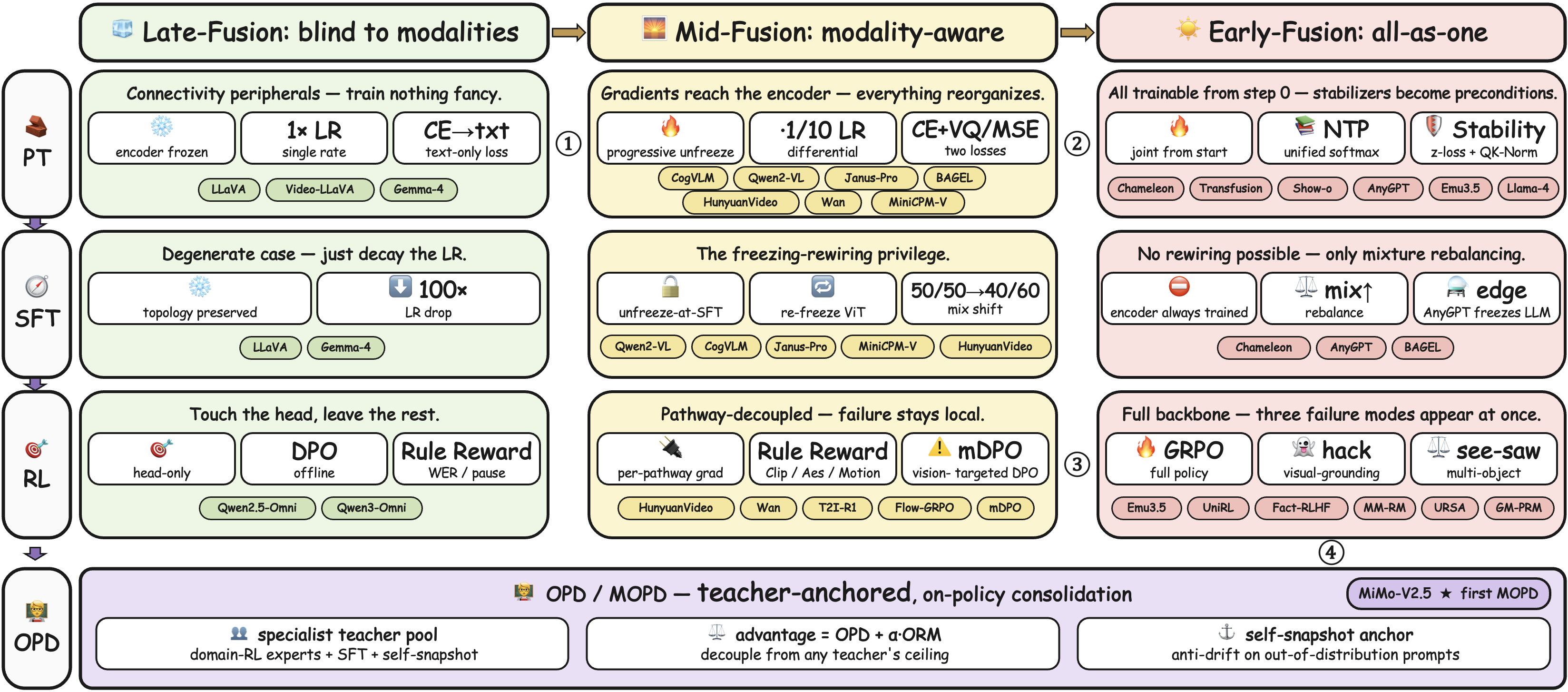
|
Understand
|
Image-Text Alignment |
LAION-5B, COCO Captions, CC3M/CC12M, YFCC100M, DataComp |
T, I |
Weakly-aligned web-scale pairs for cross-modal mapping; image-level semantics. |
| VQA & Instruction Tuning |
VQA v2, GQA, OK-VQA, ScienceQA, LLaVA-Instruct, InstructBLIP |
T, I |
Task-driven QA and multi-turn instruction-following; perception → dialogue. |
| Interleaved & Multi-Image |
MMC4, OBELICS, OmniCorpus, MANTIS, NLVR2, MuirBench, BLINK |
T, I |
Interleaved documents and multi-image reasoning; long-range dependency. |
| Document, Chart & Grounding |
DocVQA, InfographicVQA, ChartQA, TextVQA, Flickr30k Entities, RefCOCO |
T, I |
Text, layouts, charts; region-level boxes and referring expressions. |
| Video & Audio Understanding |
MSR-VTT, ActivityNet, WebVid, AudioSet, LibriSpeech, Common Voice, Clotho |
T, I, V, A |
Temporal action/event recognition, ASR, acoustic scene understanding. |
|
Generate
|
Text-to-Image & Editing |
LAION-5B, DiffusionDB, InstructPix2Pix, MagicBrush, HQ-Edit, UltraEdit |
T, I |
Synthesis or editing from prompts; controlled transformation with masks. |
| Controllable Generation |
ControlNet, GLIGEN, T2I-Adapter, Composer |
T, I + cond. |
Grounded generation with depth, sketch, layout, bounding boxes, pose. |
| Interleaved Image-Text Gen. |
VIST, OpenLEAF, CoMM, InterSyn |
T, I |
Coherent multimodal sequences (stories, tutorials) with entity consistency. |
| Video Generation |
WebVid-10M, Panda-70M, OpenVid-1M, VidGen-1M |
T, I, V |
T2V/I2V; temporal coherence, motion quality, caption recaptioning. |
| Audio & Speech Generation |
LibriTTS, VCTK, GigaSpeech, Emilia, AudioCaps, WavCaps, MusicCaps |
T, A (Sp) |
TTS, voice cloning, music and environmental sound generation. |
|
Interact
|
Web Interaction |
WebShop, Mind2Web, WebArena, VisualWebArena, WebLINX, WebVoyager |
T, I (GUI) |
Goal-driven web navigation: search, click, form fill on real/sim sites. |
| Mobile & Desktop GUI |
AITW, RICO, ScreenAI, SeeClick, OSWorld, Windows Agent Arena |
T, I (GUI) |
Screenshot/UI-tree to action; mobile and OS environments. |
| Embodied Interaction |
ALFWorld, BridgeData V2, Open X-Embodiment, Magma |
T, I, V (robot) |
Language-conditioned manipulation from visual + robot states. |
|
Align
|
Hallucination & Faithfulness |
LLaVA-RLHF, RLHF-V, VLFeedback, RLAIF-V, HA-DPO, V-DPO |
T, I |
Comparative / span-level feedback to reduce hallucinations. |
| Safety Alignment |
SPA-VL, Safe RLHF-V |
T, I |
Safe/unsafe response pairs under multimodal harmful prompts. |
| Generation Quality Pref. |
ImageReward, Pick-a-Pic, HPS v2, VBench, VBench++ |
I, V |
Aesthetics, alignment, temporal consistency, motion quality. |
| Agentic Preference |
Environment Rewards, Human Demos |
T, I, A |
Env-aligned action correctness, efficiency, recovery. |